The Turning Point in Reasoning with Large Language Models
Over the past few years, Large Language Models (LLMs) have captivated the research community, pushing boundaries with their text generation, translation abilities, and unexpected proficiency in tasks they weren’t directly trained for. Each evolution of these models has reinforced a general consensus: bigger is better. However, one persistent shortfall remains evident: reasoning skills, particularly in complex problem-solving scenarios, seem underdeveloped.
Consider multi-step math challenges or inquiries relying on common sense; these often reveal a chasm between the LLMs' fluency in language and their reasoning prowess. While the models might spit out confident answers, mere confidence isn’t sufficient. The crux lies in their ability to dissect a problem logically before arriving at a conclusion. That’s where things get tricky.
An insightful paper titled *Chain-of-Thought Prompting Elicits Reasoning in Large Language Models* shook the foundations of conventional understanding. Instead of bombarding an LLM with a problem and expecting an answer right away, the authors proposed a different strategy: encourage these models to articulate their reasoning step-by-step before reaching a final verdict.
This seemingly simple shift in approach yielded profound implications. The revelation? Many reasoning capabilities that appeared lacking weren't fundamentally absent; they just needed to be prompted in a more effective manner. This research reshaped how scholars and engineers perceive prompting and problem-solving in LLMs, providing a launching pad for a wave of subsequent developments focused on reasoning-oriented techniques.
Through this work, not only did the authors alter the conversation around LLM capabilities, but they also set the stage for an explosion of methodologies aimed at harnessing reasoning as an intrinsic quality in language models. This achievement marked a significant departure from simply querying models about what an answer is, guiding them instead on how to reach that answer methodically.
Overview of the Paper
In this discussion, we’ll closely examine the pivotal paper *Chain-of-Thought Prompting Elicits Reasoning in Large Language Models*, published by researchers from Google in 2022. It presents a groundbreaking concept—**Chain-of-Thought (CoT) Prompting**—which emphasizes that enhancing performance isn’t always about creating larger and more complex models; sometimes, it’s about refining how we engage them.
The question the authors posed was refreshingly straightforward: what happens if an LLM is prompted to reveal its reasoning journey before delivering a final answer? Rather than simply responding to prompts with an answer, they introduced a model that articulates its thought process along the way—engendering a richer and more logical approach to problem-solving.
The historical significance of this method lies in its ability to allow many of the reasoning capabilities inherent in LLMs to emerge without necessitating further training or adjustments to the underlying architecture. This marks a watershed moment, influencing an entire line of research focused on reasoning methodologies, including Self-Consistency and Process Supervision, that have flourished in the years that followed.
In essence, this paper champions a transition in our approach to LLMs: we should focus on encouraging them to map out their reasoning processes rather than merely seeking straightforward answers.
Here’s a link to the original paper, should you wish to dive deeper:
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
To aid your understanding of this review, here’s an infographic summarizing our exploration ahead.

Table of Contents:
Prerequisites
To fully appreciate this analysis, some foundational knowledge surrounding the evolution of large language models leading to Chain-of-Thought prompting is beneficial. I suggest reviewing previous articles in this series to get a grasp on the development trajectory.
Notably, the review of GPT-3 is crucial here, as the work on Chain-of-Thought prompting builds directly upon the model's innovative capability for in-context learning. It's a learning approach where adjustments to the prompt can enhance the model's comprehension without necessitating a complete overhaul or retraining.
A broader understanding of concepts in natural language processing (NLP) and transformer models will also enrich your experience. Familiarity with terms like prompting, few-shot learning, and the mechanics of token generation in language models will be immensely helpful. Additionally, grasping basic machine learning concepts and having some exposure to reasoning tasks will connect the dots nicely.
Even if math and machine learning research isn't your forte, don’t fret. I’ll present these ideas intuitively, ensuring that you comprehend why Chain-of-Thought prompting has become a pivotal reasoning technique in contemporary AI and how a straightforward prompt shift can revolutionize our understanding of language model reasoning capabilities.The findings surrounding larger language models and their affinity for chain-of-thought prompting are striking. When juxtaposing the 62 billion parameter PaLM model with its 540 billion counterpart, researchers found that scaling up significantly mitigated issues relating to semantic errors and incomplete reasoning. This isn't just about verbosity; larger models are leveraging their scale to construct reasoning chains that are not only longer but also exhibit a logical completeness that smaller models struggle to achieve.
Ablation Study
Ablation studies serve as a powerful tool in machine learning, allowing researchers to dismantle and analyze components of a model to glean insights into its performance. They differ fundamentally from standard accuracy checks by focusing on the "why" behind a model's success rather than just "if" it works. In this paper, the authors employed ablation experiments specifically to pinpoint the factors that make chain-of-thought prompting effective in enhancing reasoning.
After establishing the superiority of chain-of-thought prompting, the authors pursued a crucial inquiry: what mechanisms drive this improvement? Simply noting higher accuracy numbers isn't sufficient to capture the essence of what’s happening. So, they designed a series of experiments aimed at isolating different elements of the prompting strategy.
One hypothesis tested involved the notion that chain-of-thought prompting aids models by prompting them to formulate mathematical equations prior to providing answers. If this were the case, one might think that natural language reasoning wouldn't be essential. However, when the researchers replaced reasoning steps with equations alone, performance enhancements on complex tasks like GSM8K were minimal. Equations alone tended to assist in simpler problems, underscoring that complex tasks necessitate a deep understanding of the questions—more than straightforward mathematical translations convey.
The authors explored another angle: could chain-of-thought prompting's advantages stem simply from enabling larger token generation, allowing models to allocate more computational resources to challenging problems? They developed prompts that generated a higher number of tokens without imparting any meaningful reasoning. The outcome? Performance metrics remained nearly indistinguishable from standard prompting approaches, suggesting that it wasn't merely the extra computational steps that mattered but the reasoning embedded within them.
A further possibility considered was that these prompts merely triggered recollections of relevant knowledge within the model's architecture. If this were true, the reasoning steps wouldn't need to precede the final answer. Testing this notion, the authors rearranged the process to place reasoning after the final answer. Once more, results reverted largely to baseline performance. This indicated that the sequential presentation of reasoning steps actively influences the model's ability to reach correct conclusions instead of just being an afterthought.
Ultimately, these investigations reinforce the central thesis of the paper: the benefits of chain-of-thought prompting can't be attributed solely to equation generation, computational increments, or easy access to pre-stored knowledge. Instead, it's the reasoning process itself that's crucial, with intermediate reasoning steps acting as vital guides through complex problem-solving scenarios.
Robustness of Chain-of-Thought Prompting
Concerns about the variability of prompting methods are longstanding, particularly regarding their susceptibility to subtle changes in phrasing or the selection of examples. In this context, the authors sought to discern whether the gains from chain-of-thought prompting were genuinely robust or merely the result of specific, carefully curated demonstrations.
To tackle this issue, they tasked multiple authors with independently crafting reasoning traces for the same examples. Additionally, they explored different writing styles and constructed prompts from completely new sets of examples. The goal was to establish whether the effectiveness of chain-of-thought prompting could be ascribed to a specific wording or if it lay in the fundamental reasoning structure itself.
The results were encouraging: variations stemming from individual writing styles or specific word choices did not dramatically diminish the advantages of chain-of-thought prompting. Across different approaches, every version consistently outperformed standard prompting by a solid margin. While some degree of performance fluctuation could still be observed among varying prompts, the essential finding remained robust: chain-of-thought methods yielded superior outcomes irrespective of prompt design nuances.
The authors expanded their analysis further by manipulating the order and the quantity of exemplars in the prompts. The same pattern emerged: the core success of chain-of-thought prompting didn’t hinge on a single perfect prompt. Rather, it emphasized that the underlying power of the reasoning process itself could be beneficial in a multitude of contexts, as long as some form of structured reasoning was introduced.
This aspect tremendously strengthens the paper’s claim: the efficacy of chain-of-thought prompting is not a mere byproduct of how well a prompt has been crafted but a manifestation of a reasoning process that has broader applicability.As we conclude this exploration of AI's evolution, it becomes abundantly clear that a paradigm shift has taken place in how we regard the capabilities of language models. The emergence of techniques like Chain-of-Thought Prompting has fundamentally altered the focus of research from merely what these models can regurgitate to how they actually think, strategize, and tackle challenges. This shift is more significant than it might initially appear; it suggests that the latent potential within these systems is not merely a question of training data but one of conditions and frameworks that can unlock their reasoning abilities.
Looking back, it's hard to overstate the impact of Chain-of-Thought Prompting. This approach didn't just carve out a new avenue for prompting; it revealed that language models possess a dormant reasoning capacity waiting to be harnessed under the right circumstances. This understanding encourages researchers to push further, experimenting with innovative methods like Self-Consistency and process supervision, which are fostering newer generations of models adept at understanding and verifying complex problems.
The infographic below succinctly illustrates this trajectory, charting key works from the advent of GPT-1 to the latest iterations that emphasize reasoning capabilities. Each milestone—be it instruction tuning, the rise of Self-Consistency, or advanced reasoning-focused designs—adds nuance to our understanding of how language models have progressed from basic predictive tasks to sophisticated problem solvers.
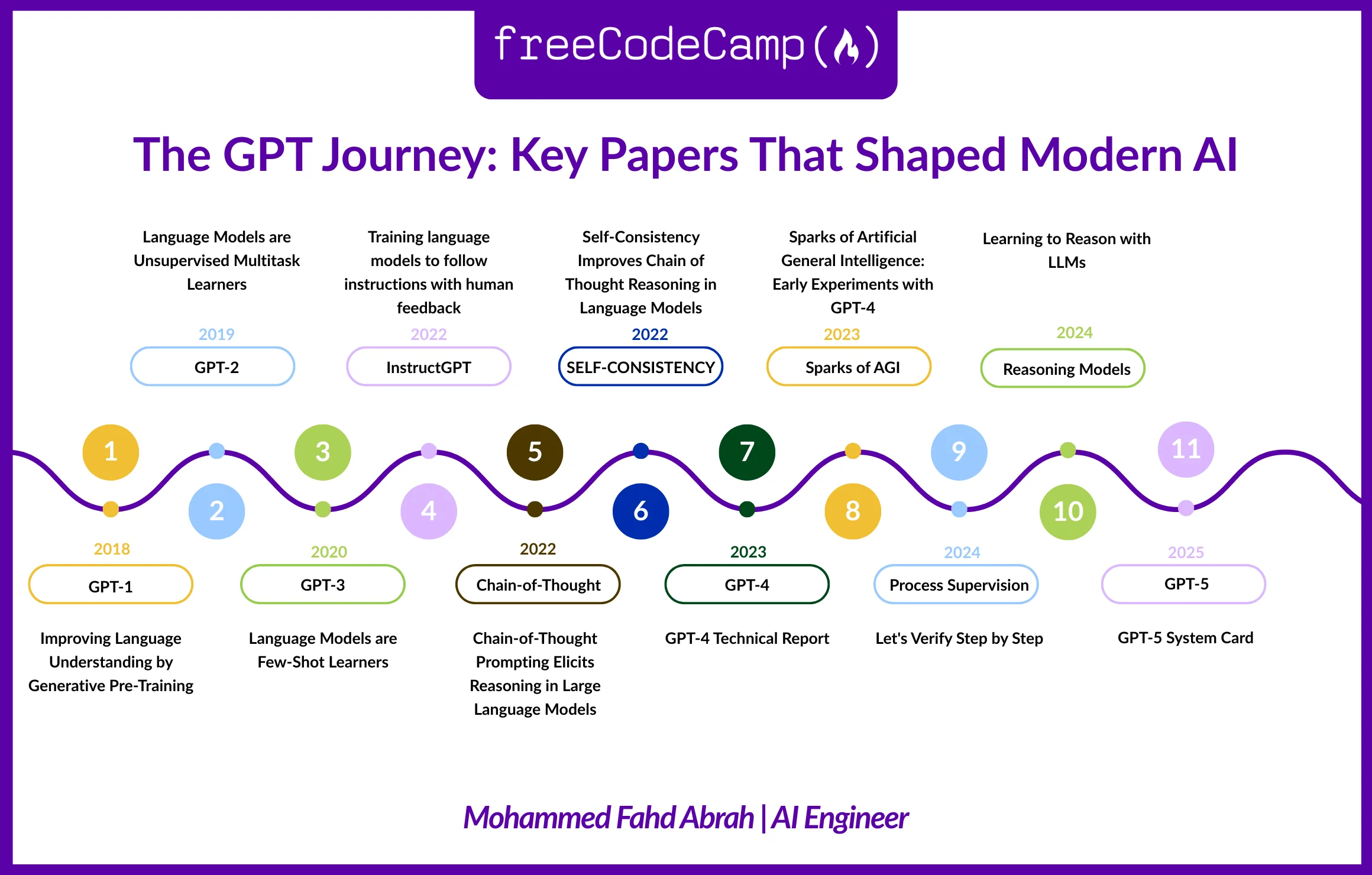
While the path ahead seems promising, we should remain skeptical about how quickly these advancements will translate into practical applications. If you’re engaged in this space, consider the implications of these findings. The landscape is shifting, but how effectively can we harness these evolving capabilities for real-world solutions? That question lingers as we watch AI continue to unfold its potential.